
1. Spark
Introduced by Apache, it is a powerful big data processing engine which can stream huge volume of data and ingestion of data. The best thing about spark is its ability to process the billions of records of data and using powerful in-memory technique to achieve it. Spark comes in different languages like phython, scala, java and more. Spark comes with whole of different components like streaming, sql ingestion, graph, machine learning libraries and more.

Spark is well know for powerful computing of big data over distributed clusters. Spark gives flexibiity for the user to override default spark properties and gives full control to the developers to fine tune the application according to their needs.
2. Spark Steaming
Spark Streaming basically streams incoming data and ingest the data into any sql engines or file systems or publish the data. The spark streaming flow allows the application to consume the incoming data, the data can be coming through any producers who is publishing data using any distributed messaging frameworks like kafka. The spark streaming can be done either by using direct streaming, or structured streaming and write the data to wherver it is intended for. The initial version of spark 1.x was mainly supporting direct streaming and later Apache introduced spark structured streaming which reduced lot of bioler plate code.
In most case, spark streaming is used along with Kafka, and it is well integrated with any No SQl databases.
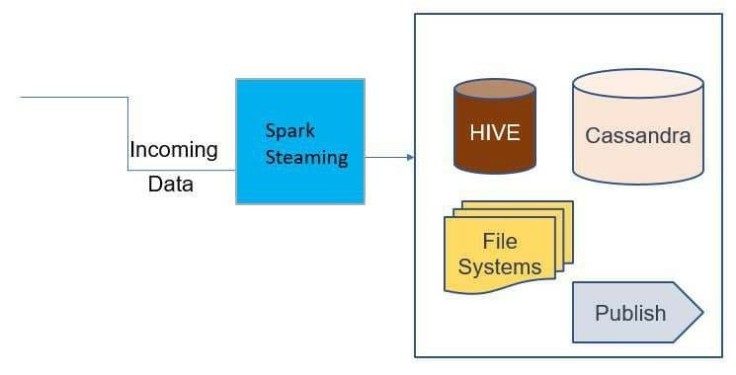
2.1 Spark Streaming Flow
To set up a streaming job,
We require configuration details like for instance in case of Kafka we need what are kafka brokers, kafka topic name, and Kafka Consumer, Kafka Java Keystore location and password. These configuration can be passed as parameters for either structured streaming or direct streaming api's.
Once the streaming code is implemented, next task is to implement data ingestion flow, like where we want to write this data. Spark goes well along with hive, hbase, cassandra etc, so based on requirement spark streaming can convert its RDD to dataset and further dataset can write to tables or file system.
To kickstart spark streaming flow, we need spark submit command along with spark properties, which is a triggerring point for spark job.
Once we are ready with all above steps, spark streaming job is good to start. Spark also comes with UI, which can be used for monitoring the job statistics and metrics.
Spark submit is simple command which can be configurable
in a shell script to run. The command has path for spark- submit along with spark properties and actual class to invoke and the jar location. Spark job can be submitted in either cluster mode or locally.
Spark Configuration plays a key role in overall performance
of job and settings. In the configuration you can specify driver memory, number of executor cores, and number of executor instances and executor memory. This configuration purely depends on volume of data your job is going to process and tune it accordingly. There are tons of different configuration settings that spark provides which is documented in official site. Some additional settings like hearbeat interval, cleaning intervals , backpressure all these also plays vital role.
2.2 Spark Streaming Uses
Spark streaming job serves different uses cases. Unlike traditional maprecude hadoop jobs which depends on disk for read and write, spark can do it in memory and also it can customize to do both in memory and disk by simple settings. This makes Spark a great tool to process and transform huge volume data.
Spark is well integrable with any stacks like kafka, cassandra, hive, hdfs, MQ, flumes, Kinesis and more. This makes great choice whenever we want to ingest into any of the data stores. Development wise it less coding and more time is spent on tunning the job to meet the performance goal.
Spark help processing and computing big data over distributed cluster. This data can be used for analytics, machine learning and also building artifical intelligence insights.
Spark streaming ultimately serves the purpose of building live dashboards, reporting, smart data analytics. The uses are unlimited, due to its unique processing power it is a number one choice when huge volume of data needed to be processed.
Acknowledgements
My profound experiences I have in infirmation technology field, give me a vision to contribute to build these kind of tools. I am very thankful to my past and present company to give me an opportunity to explore a way to solve a industry problems.
Sudhish Koloth is a Lead developer working in Banking and Financial company. He has 13+ years of working experience in information technology. He worked in various technologies including Full stack, big data, automation and android development.








